How Programmatic Intelligence Transforms Financial Data Processing Beyond What Gen AI Alone Can Achieve
Why Python Is Still the Bedrock of Financial Intelligence
In the era of large language models and no-code AI platforms, it might seem counterintuitive to argue for Python as a cornerstone of financial data intelligence. Yet for any financial institution dealing with complex modeling, regulatory computation, or derivative pricing, the reality is clear: natural language AI alone cannot replace the precision, reproducibility, and mathematical rigor that Python-based agents provide.
The Table AI Python agent does not compete with LLMs — it complements them. The LLM understands intent, context, and semantics. The Python agent executes the precise, deterministic logic that financial calculations demand. Together, they form an intelligence layer that is both interpretable and powerful.
Complex Logic in Financial Processing: A Deep Dive
Consider the calculation of a Weighted Average Cost of Capital (WACC) for a portfolio company under LBO analysis. This is not a simple formula — it requires pulling market data for comparable companies, computing beta levered and unlevered, applying a capital structure assumption, incorporating tax shield effects, and adjusting for size and illiquidity premiums. Each step involves conditional logic, exception handling, and domain-specific rules.
A naive AI system asked to ‘calculate WACC’ will produce a plausible-looking answer that may be subtly wrong in ways that only an experienced investment banker would catch. The Python agent, by contrast, executes a deterministic algorithm with explicit assumptions, documented intermediate steps, and validation checks at each stage.
💡 Use Case: An investment bank’s M&A team used the Python agent to automate WACC calculations across 200 potential acquisition targets simultaneously, with each calculation fully auditable and reproducible. What previously took 3 analysts 2 weeks was completed overnight.
In the loan industry, complex logic appears in risk scoring models. A FICO score is just the beginning — sophisticated lenders apply overlay models that adjust scores based on behavioral data, macroeconomic factors, and portfolio-level concentration risk. These models involve hundreds of conditional rules, lookup tables, and machine learning features that must be applied consistently and at scale.
Machine Learning and the Creation of Aliases
One of the most underappreciated problems in financial data engineering is the alias problem: the same real-world entity appears under different names across different systems, and nobody has a master mapping.
In a large bank, a single commercial borrower — say, a mid-size manufacturing company — might appear as ‘Acme Manufacturing Inc.’ in the core banking system, ‘ACME MFG’ in the treasury system, ‘Acme Manufacturing, Incorporated’ in the legal documentation system, ‘Acme-Manufacturing’ in the credit risk database, and ‘ACMEMFG001’ as an internal code in the trading platform. These are all the same entity. Without alias resolution, risk aggregation is impossible.
The Python agent uses machine learning to build and maintain an alias registry — a dynamic mapping that links all known representations of an entity to its canonical identity. This goes beyond fuzzy string matching. The ML model incorporates:
• Entity embedding — representing company names as vectors in a semantic space where similar names cluster
• Structural similarity — identifying patterns like abbreviations, legal suffix variations (Inc./LLC/Corp.), and punctuation normalization
• Behavioral correlation — two entities that always appear in the same transactions are likely the same entity
• External reference anchoring — matching against DUNS numbers, LEI codes, and EIN/TIN identifiers to ground aliases in authoritative external registries
• Temporal tracking — maintaining alias history so that a company’s name change in 2019 does not break analysis that spans pre- and post-name-change records
💡 Use Case: A commercial bank discovered through alias ML that their top-10 commercial borrower — when all aliases were resolved — had $2.3B in aggregate exposure across subsidiaries that had each been treated as independent borrowers in their credit risk system. This was a significant concentration risk violation that had been invisible in every prior risk report.
The Residential Mortgage Alias Problem
In residential mortgage servicing, aliases appear in a different but equally critical form: property address normalization. A single property might be recorded as ‘123 Main St.’, ‘123 Main Street’, ‘123 Main St, Apt 1’, ‘123 MAIN ST #1’, and ‘One Twenty-Three Main Street’ across different systems. For mortgage servicers tracking lien positions, flood zone determinations, and property tax payments, these inconsistencies create real financial risk.
The ML alias engine normalizes addresses to a canonical form using the USPS standardization rules, geocoding validation, and APNs (Assessor Parcel Numbers) as authoritative identifiers. But it goes further — it also identifies when two loans are secured by the same property, even when the property records have never been formally linked. This is critical for identifying unreported subordinate liens and for accurately modeling collateral concentration in mortgage-backed securities.
Python Agent + LLM: The Collaboration Architecture
The most powerful architecture is not Python alone or LLM alone — it is a structured collaboration between them. The LLM interprets the business question, identifies the relevant data sources and fields, and generates a computational plan. The Python agent executes that plan with precision, validates the results against domain constraints, and returns structured output that the LLM then interprets and communicates.
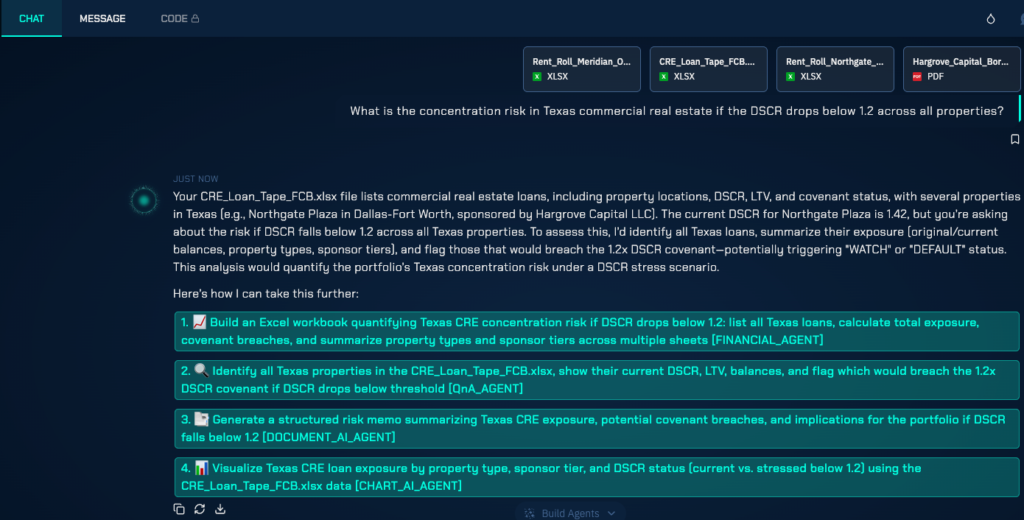
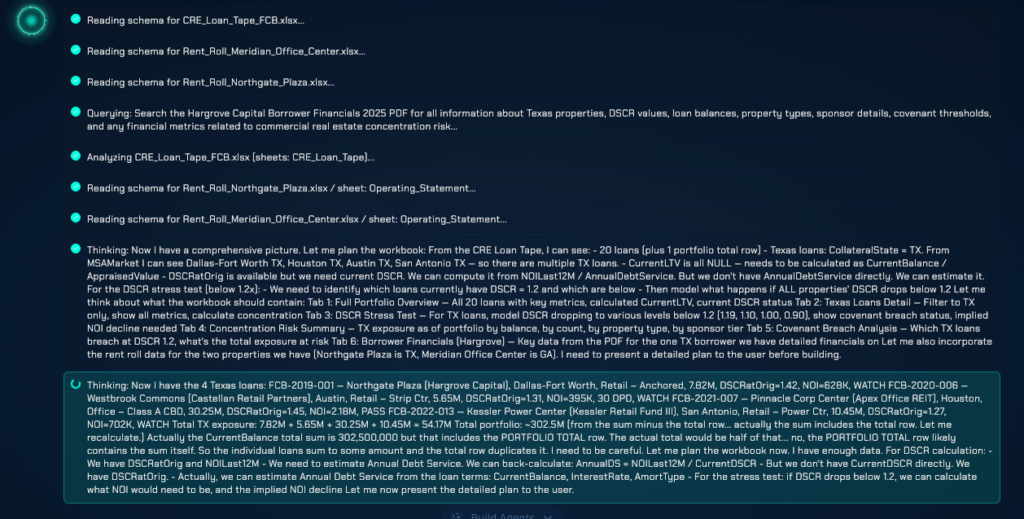
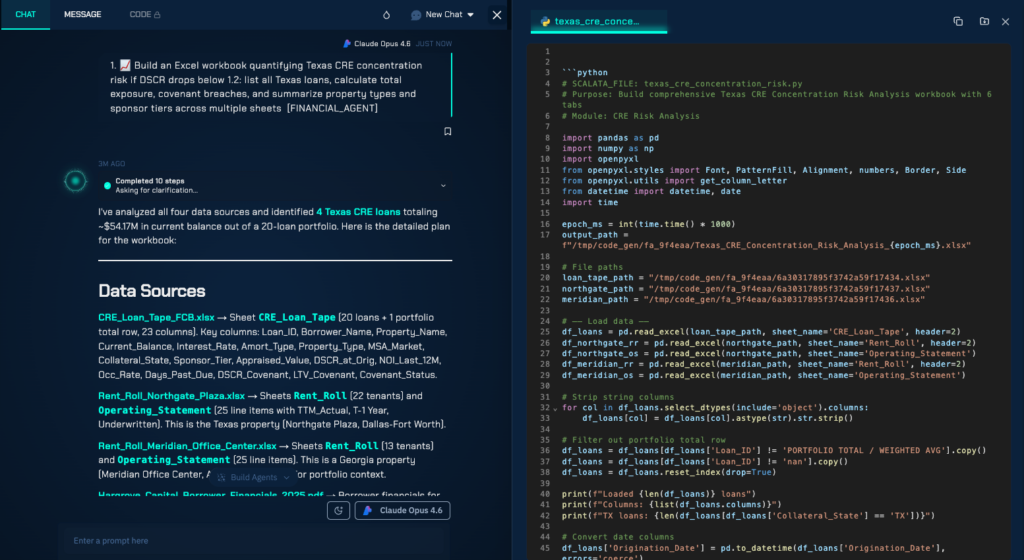
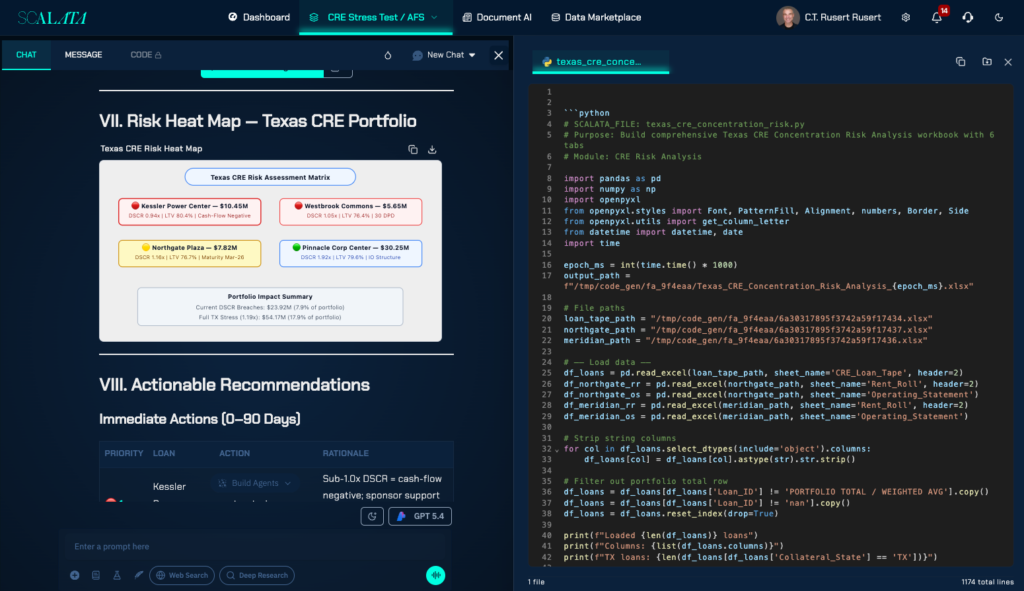
This architecture means that a portfolio manager can ask ‘What is our concentration risk in Texas commercial real estate if DSCR drops below 1.2 across all properties?’ in plain English, and receive a precise, auditable answer — with the Python agent handling the SQL generation, the DSCR recalculation logic, the geographic filtering, and the portfolio aggregation, while the LLM handles the interpretation of the question and the communication of the result.